#Library Imports
import numpy as np
import pandas as pd
import math
import os
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
#######통계 라이브러리##########
from statsmodels.tsa.arima.model import ARIMA
train=pd.read_csv('train.csv', encoding='cp949')
test=pd.read_csv('test.csv', encoding='cp949')
train['비전기냉방설비운영'].fillna(0, inplace=True)
train['태양광보유'].fillna(0, inplace=True)
submission=pd.read_csv('sample_submission.csv')
#train.shape 122400 X 10
#60개의 건물 X 85일 24시간 =122400
train
#test.shape 10080 X 9
#60개의 건물 X 7일 24시간 =10080
test
모델링¶
#2d의 데이터프레임을 건물별 정보를 반영한 3d 데이터로 변환
def df2d_to_array3d(df_2d):
feature_size=df_2d.iloc[:,2:].shape[1]
time_size=len(df_2d['date_time'].value_counts())
sample_size=len(df_2d.num.value_counts())
return df_2d.iloc[:,2:].values.reshape([sample_size, time_size, feature_size])
train_x_array=df2d_to_array3d(train)
test_x_array=df2d_to_array3d(test)
print(train_x_array.shape)
print(test_x_array.shape)
def plot_series(x_series, y_series):
#입력 series와 출력 series를 연속적으로 연결하여 시각적으로 보여주는 코드 입니다.
plt.plot(x_series, label = 'input_series')
plt.plot(np.arange(len(x_series), len(x_series)+len(y_series)),
y_series, label = 'output_series')
plt.axhline(1, c = 'red')
plt.legend()
idx=1
x_series=train_x_array[idx, :, 0]
model=ARIMA(x_series, order=(3, 0, 1))
fit=model.fit()
preds=fit.predict(1, 168, typ='levels')
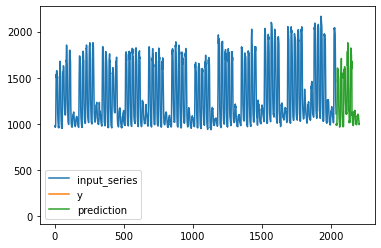
plt.plot(x_series, label = 'input_series')
plt.plot(np.arange(2040, 2040+168), test_x_array[idx, :, 0], label='y')
plt.plot(np.arange(2040, 2040+168), preds, label='prediction')
plt.legend()
valid_pred_array=np.zeros([60, 168])
for idx in range(train_x_array.shape[0]):
try:
try:
x_series=train_x_array[idx, :, 0]
model=ARIMA(x_series, order=(5, 1, 1))
fit=model.fit()
preds=fit.predict(1, 168, typ='levels')
valid_pred_array[idx, :]=preds
except:
print("order 4,1,1")
x_series=train_x_array[idx, :, 0]
model=ARIMA(x_series, order=(4, 1, 1))
fit=model.fit()
preds=fit.predict(1, 168, typ='levels')
valid_pred_array[idx, :]=preds
except:
print(idx, "샘플은 수렴하지 않습니다.")
valid_pred_array.shape
submission['answer']=valid_pred_array.reshape([-1,1])
submission
submission.to_csv('baseline_submission2.csv', index=False)